Quantum Research Center Popular Science: The Geometric Contour of Data—From Topological Data Analysis to the Exponential Advantage of Quantum Algorithms
Quantum Research Center Popular Science: The Geometric Contour of Data—From Topological Data Analysis to the Exponential Advantage of Quantum Algorithms
Post Date
April 17, 2026
Topic
Centers

Speaker: Dr. Kuo-Chin Chen
I. Introduction: A Geometric Perspective Breaking Through Traditional Dimensionality Reduction
In the contemporary era of Big Data and machine learning, we frequently need to process complex point cloud data from various domains. This data is often high-dimensional and accompanied by a significant amount of noise. Traditional data processing paradigms mostly rely on dimensionality reduction techniques like Principal Component Analysis (PCA) or clustering algorithms based on local distance metrics. However, when these conventional methods forcefully project high-dimensional data into lower-dimensional spaces or process manifolds with irregular structures, they are highly prone to destroying the intrinsic "global geometric structure" of the data, leading to the loss of critical features.
To address this pain point, Topological Data Analysis (TDA) has emerged as a highly anticipated frontier field in applied mathematics and data science in recent years. Topology, as a core branch of mathematics, inherently studies the properties of space that remain invariant under continuous deformations (such as stretching and twisting, but excluding tearing or gluing). The revolutionary perspective of TDA lies in the fact that it no longer treats data simply as isolated coordinate points in Euclidean space, but rather views the entire dataset as a geometric complex with a specific "shape." By extracting topological invariants from the dataset, we can obtain robust features that are immune to local noise and coordinate transformations, thereby revealing hidden global patterns within complex data.
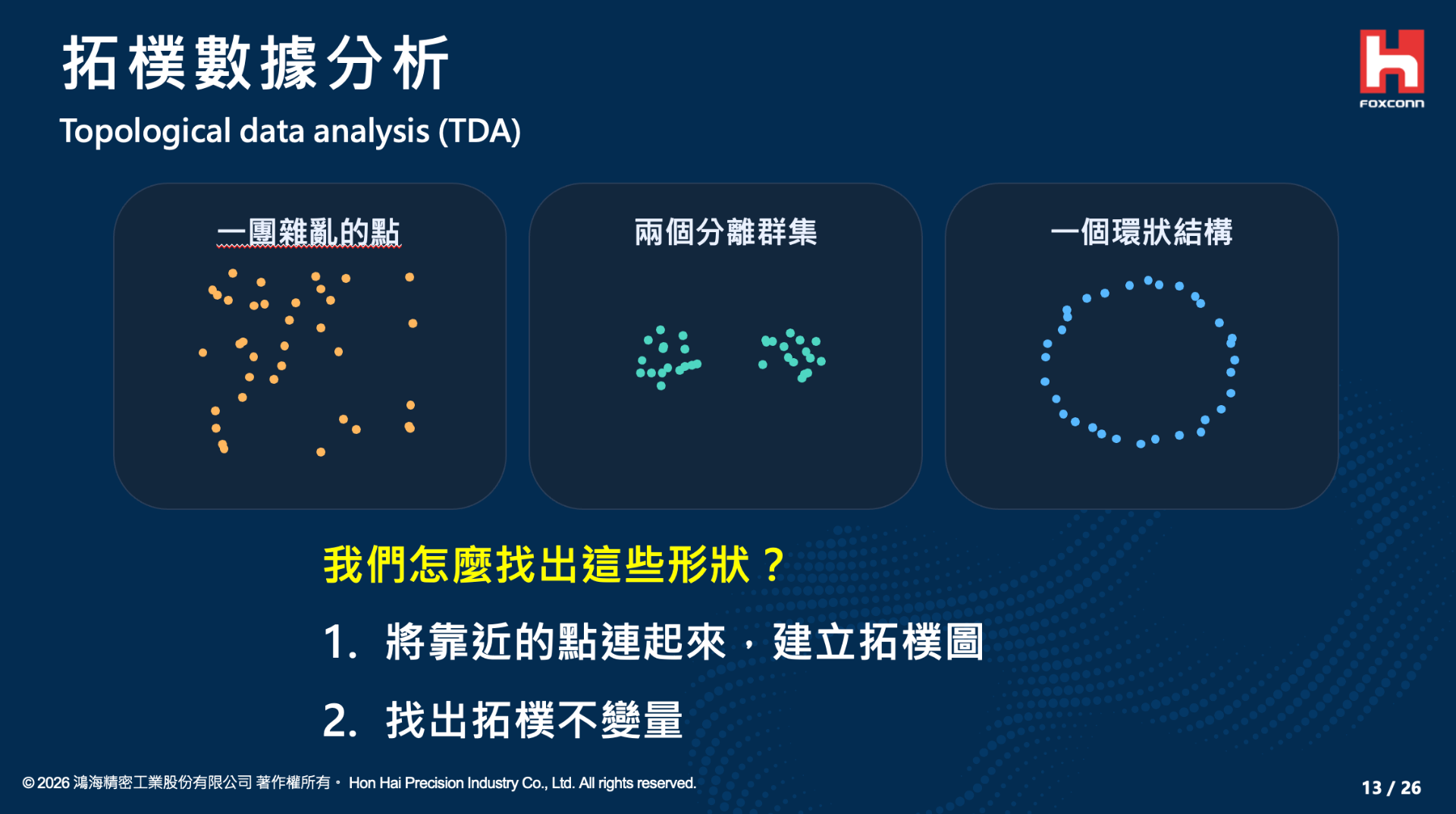
II. The Mathematical Foundation of TDA: Simplicial Complexes, Persistent Homology, and Betti Numbers
To understand the operational mechanism of TDA, we must first explore how to transform discrete data points into continuous topological structures. The core step relies on the construction of a Simplicial Complex, with the Vietoris-Rips complex being the most commonly used in our practice.
Assuming we have a set of discrete data points, we set a continuously expanding radius $r$ for each point. When the distance between two points is less than $2r$, we connect them with a line segment (a 1-dimensional simplex, or edge); when three points are pairwise connected, they form a solid triangle (a 2-dimensional simplex); and so on up to higher-dimensional tetrahedra. As the scale $r$ gradually increases from $0$, the data points progressively intertwine to form a complex geometric network.
During this dynamic expansion process, the topological features of the data will successively experience "birth" and "death." In our research, we utilize the theory of Persistent Homology from algebraic topology to precisely record the lifecycles of these features. The key mathematical metrics used to quantify these topological features are called Betti Numbers ($\beta_k$):
$\beta_0$: Represents the number of connected components in the space.
$\beta_1$: Represents the number of one-dimensional loops in the space.
$\beta_2$: Represents the number of two-dimensional enclosed voids in the space.
By plotting the survival intervals of these topological features into a "Persistence Barcode" or "Persistence Diagram," we can filter out short-lived noise and extract the persistent topological features that represent the true shape of the data.

III. The Curse of Dimensionality: An Insurmountable Barrier for Classical Computers and Traditional Simulation
Although TDA perfectly aligns with the analytical needs of complex data in theory, when we attempt to implement it on classical computers, we face an unavoidable "Curse of Dimensionality."
In algebraic topology, to calculate the $k$-th Betti number $\beta_k$, we must compute the dimensional difference between the kernel and the image of the boundary operator $\partial_k$. This is generally equivalent to finding the dimension of the null space of the combinatorial Laplacian $\Delta_k$. However, for a dataset containing $N$ data points, the total number of $k$-dimensional simplices reaches the combinatorial number $\binom{N}{k+1}$.
This means that as the number of data points $N$ or the required dimension $k$ increases, the number of simplices will experience exponential growth. On classical supercomputers, when confronted with high-dimensional complex networks possessing thousands of nodes, the dimension of the Laplacian matrix will rapidly expand beyond the storage limits of all existing memory, let alone performing diagonalization or Singular Value Decomposition (SVD).
It is worth noting that even by utilizing advanced classical algorithms, or attempting to leverage classical simulations of quantum circuits (such as using the stabilizer formalism to handle specific sub-problems), we cannot effectively overcome this complexity barrier fundamentally driven by a combinatorial explosion. This is an algebraic geometry challenge that intrinsically demands massive memory space and staggering computational power.
IV. The Breakthrough of Quantum Computing: From Exponential Complexity to Polynomial Time
Facing this seemingly unsolvable classical puzzle, quantum algorithms demonstrate an absolute Computational Advantage, which is also the core focus of our research in the field of quantum computing. The most famous representative is the Lloyd-Garnerone-Zanardi (LGZ) algorithm, which ingeniously transforms the computation of topological features into an eigenvalue problem within a quantum system.
Efficient Mapping to Hilbert Space (Qubit Mapping):
The bottleneck of classical computation lies in memory, and the superposition states of quantum mechanics offer us a solution. For $N$ data points, we only need $N$ qubits to construct a Hilbert space $\mathcal{H}$ with $2^N$ dimensions. Each basis state in the system (e.g., $|1010...0\rangle$) can directly correspond to a specific simplex ($1$ represents the vertex is included in the simplex, $0$ represents its absence). This mapping successfully compresses the "exponential memory" required by classical computers into a "linear number of qubits" on a quantum computer.
Hamiltonian Formulation:
According to Hodge Theory, the $k$-th dimensional Betti number $\beta_k$ is exactly equal to the number of zero eigenvalues of the combinatorial Laplacian $\Delta_k$. When designing the quantum algorithm, we map the boundary operator and its adjoint operator to creation and annihilation operators on the quantum system, thereby constructing the corresponding Hamiltonian:
$$\Delta_k = \partial_k^\dagger \partial_k + \partial_{k+1} \partial_{k+1}^\dagger$$
The problem of finding Betti numbers is thus transformed into measuring the probability of this Hamiltonian being in its ground state (with an eigenvalue of zero).
Quantum Phase Estimation (QPE):
This is the core engine of the quantum algorithm's acceleration. By subjecting the aforementioned Hamiltonian to unitary evolution $e^{-i\Delta_k t}$, we can use the QPE algorithm to read out the phase (i.e., the eigenvalue) of the system with high precision. By statistically measuring the proportion of zero eigenvalues in our results, we can estimate the dimension of the null space, and consequently calculate the Betti number $\beta_k$. Compared to the $O(2^N)$ complexity of classical algorithms, the quantum TDA algorithm can complete the estimation of Betti numbers in polynomial time $O(poly(N))$, achieving a theoretical exponential speedup.
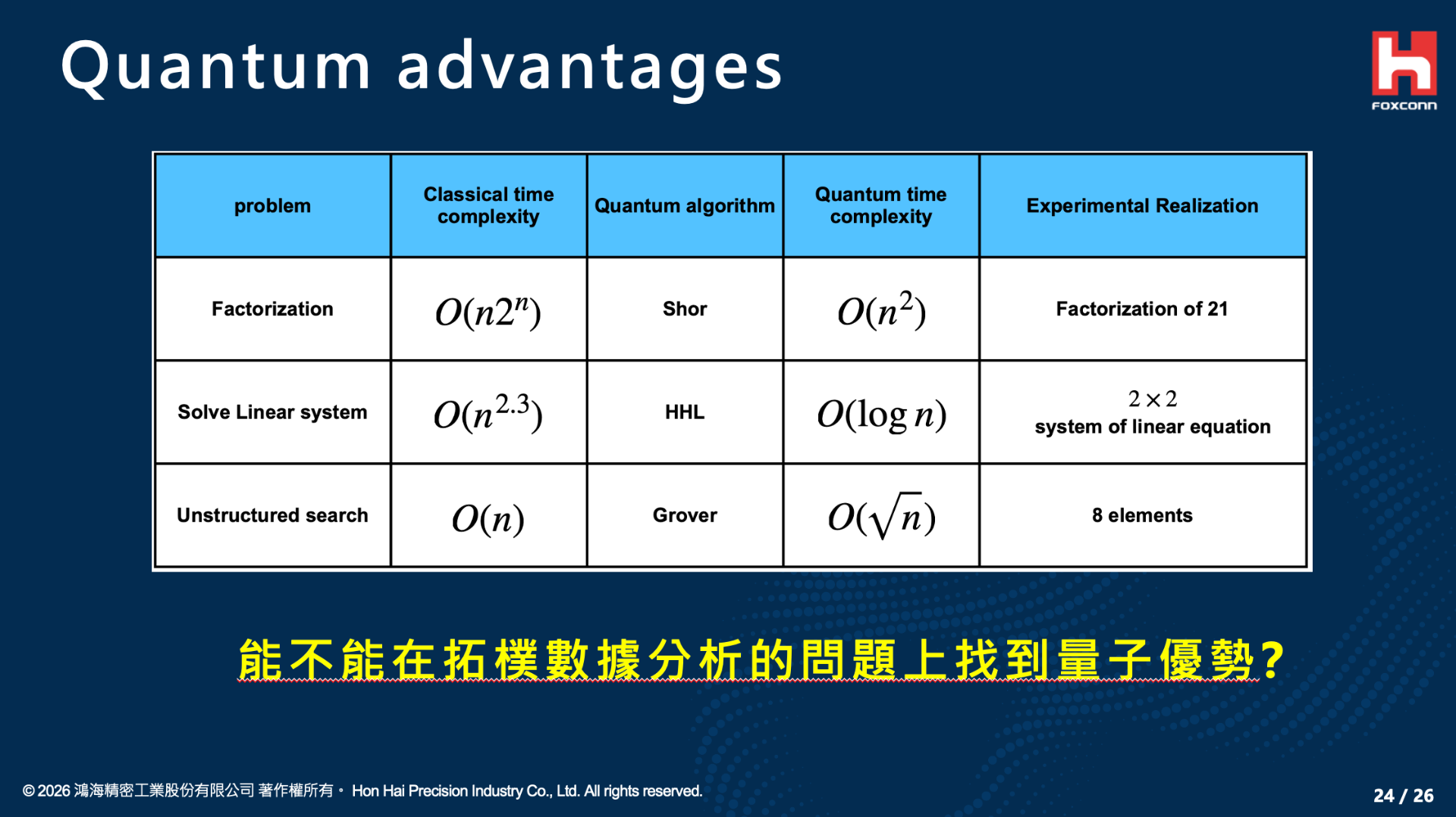
V. Conclusion and Future Practical Challenges
Finally, we must pragmatically view the future challenges. While the quantum TDA algorithm demonstrates astonishing computational advantages within mathematical frameworks and confirms the immense potential of quantum computers in processing high-dimensional topological data, we still have a long way to go before applying it to massive, real-world datasets (such as financial market forecasting, complex novel drug molecule design, and high-dimensional machine learning).
In the current Noisy Intermediate-Scale Quantum (NISQ) era, hardware limitations remain the most significant obstacle. The Quantum Phase Estimation (QPE) relied upon by quantum TDA requires the execution of deep quantum circuits, which are highly susceptible to disruption from decoherence and various Pauli noises on existing quantum hardware. Therefore, for this technology to achieve true practical utility, the future must absolutely rely on the realization of Fault-Tolerant Quantum Computing (FTQC). This requires not only mitigating noise at the hardware level but also pairing it with quantum error-correcting codes that possess high encoding rates and excellent distance properties (such as quantum low-density parity-check codes, qLDPC) to protect the logical qubits of deep circuits.
In summary, this is not only a brilliant symphony of mathematics and physics but also clearly outlines the future blueprint of quantum computing. Data indeed has shape, and only fault-tolerant quantum algorithms will serve as our most powerful microscope to discern these high-dimensional contours and unlock the computational limits of the next generation.

Building Efficient Algorithms with Error Correction, Clustering, and Noise Mitigation

Quantum Research Center Popular Science Talk:A story in computation
Quantum Research Center Popular Science Talk:Quantum Cryptography with Certified Deletion