量子所科普:資料的幾何輪廓——從拓樸數據分析到量子演算法的指數級優勢
量子所科普:資料的幾何輪廓——從拓樸數據分析到量子演算法的指數級優勢

講者:陳國進 博士
一、 緒論:突破傳統維度降維的幾何視角
在當代巨量資料(Big Data)與機器學習的範疇中,我們經常需要處理來自各個領域的複雜點雲(Point Cloud)數據。這些數據往往具有極高的維度,且伴隨著大量的雜訊。傳統的數據處理思維,多半依賴如主成分分析(PCA)等降維技術,或是基於局部距離度量的分群演算法。然而,這些傳統方法在將高維數據強行投影至低維空間,或是處理結構不規則的流形(Manifold)時,極易破壞數據內蘊的「全域幾何結構」,導致關鍵特徵的流失。
為了解決這項痛點,拓樸數據分析(Topological Data Analysis, 簡稱 TDA) 成為近年來應用數學與資料科學界高度矚目的前沿領域。拓樸學(Topology)作為數學的核心分支,其本質在於研究空間在經歷連續形變(如拉伸、扭曲,但不包含撕裂或黏合)後,依然保持不變的性質。TDA 的革命性視角在於:它不再單純地將資料視為歐幾里得空間中孤立的座標點,而是將整個數據集視為具有特定「形狀」的幾何複合體。透過提取數據集中的拓樸不變量,我們能夠獲得不受局部雜訊與座標變換干擾的穩健(Robust)特徵,從而在複雜數據中看見隱藏的全局規律。
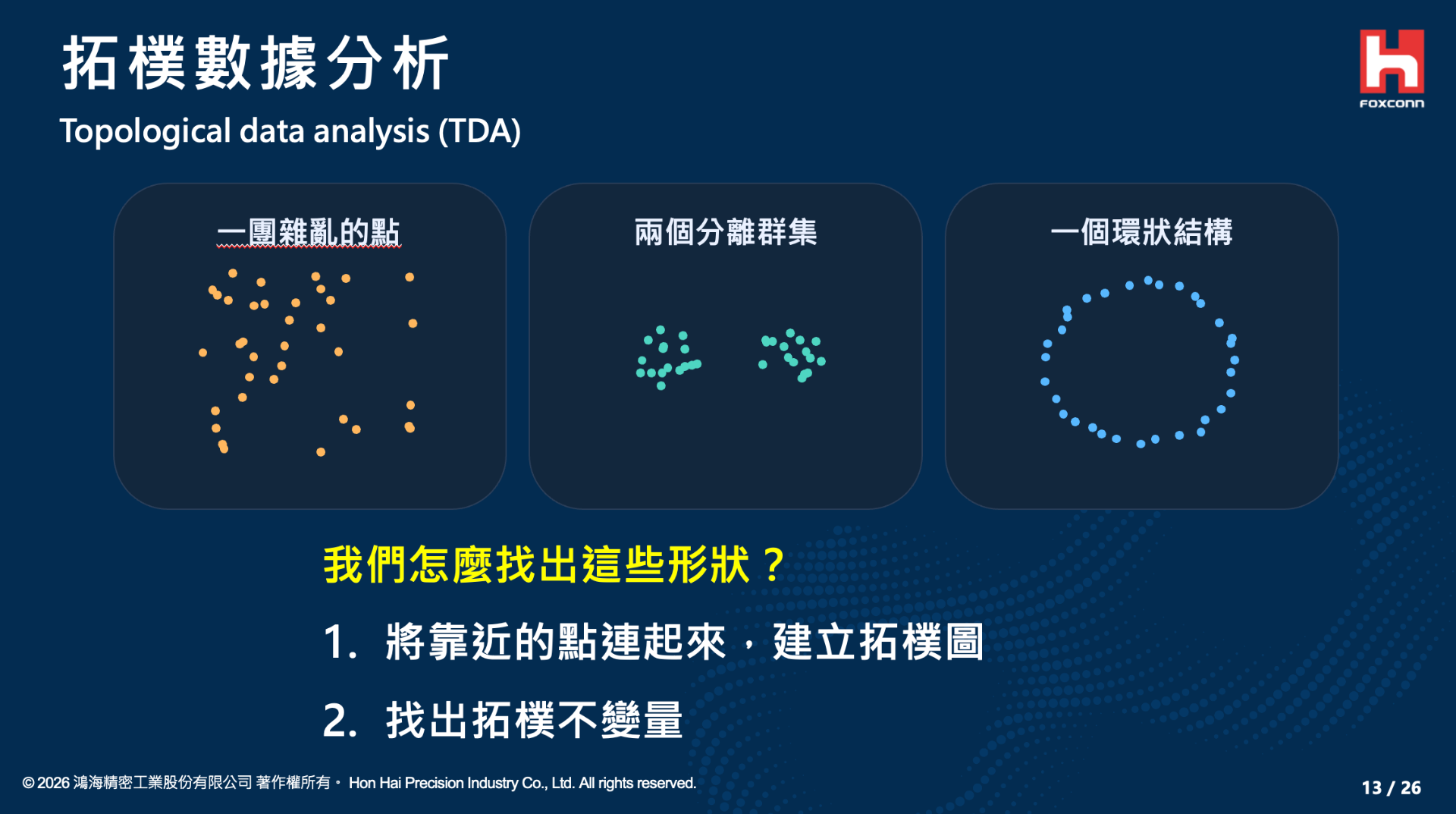
二、 TDA 的數學基石:單純複形、持續同調與貝蒂數
要理解 TDA 的運作機制,我們必須先探討如何將離散的資料點轉化為連續的拓樸結構。其核心步驟依賴於單純複形(Simplicial Complex)的建構,實務上我們最常使用的是 Vietoris-Rips 複形。
假設我們有一組離散的資料點,我們為每個點設定一個不斷擴張的半徑 $r$。當兩個點的距離小於 $2r$ 時,我們便用一條線段(1維單純形,即邊)將其連接;當三個點兩兩相連時,便形成一個實心的三角形(2維單純形);以此類推至更高維度的四面體等。隨著尺度 $r$ 從 $0$ 逐漸增加,數據點會逐漸交織成一個複雜的幾何網路。
在這個動態擴張的過程中,數據的拓樸特徵會隨之「誕生」(Birth)與「死亡」(Death)。在研究中,我們透過代數拓樸中的持續同調(Persistent Homology)理論,精確地記錄這些特徵的生命週期。而用來量化這些拓樸特徵的關鍵數學指標,稱為貝蒂數(Betti Numbers, $\beta_k$):
$\beta_0$:表示空間中連通分支(Connected Components)的數量。
$\beta_1$:表示空間中一維的環狀結構或洞(Loops)的數量。
$\beta_2$:表示空間中二維的封閉空洞(Voids)的數量。
藉由將這些拓樸特徵的存活區間繪製成「持續條碼(Persistence Barcode)」或「持續圖(Persistence Diagram)」,我們便能過濾掉生命週期極短的雜訊,粹取出代表數據真實形狀的長效拓樸特徵。

三、 維度詛咒:古典計算機與傳統模擬的難以跨越之壁
儘管 TDA 在理論上完美契合了複雜資料的分析需求,但當我們試圖在古典電腦上進行實作時,卻面臨著無法迴避的「維度詛咒(Curse of Dimensionality)」。
在代數拓樸中,要計算第 $k$ 個貝蒂數 $\beta_k$,我們必須計算邊界算子(Boundary Operator) $\partial_k$ 的核(Kernel)與像(Image)的維度差異。這通常等價於求解組合拉普拉斯矩陣(Combinatorial Laplacian) $\Delta_k$ 的零空間(Null space)維度。然而,對於一個包含 $N$ 個資料點的數據集,構成 $k$ 維單純形的總數高達組合數 $\binom{N}{k+1}$。
這意味著,隨著數據點 $N$ 或是所求維度 $k$ 的增加,單純形的數量會呈現指數級別(Exponential growth)的暴增。在古典超級電腦上,當面對擁有數千個節點的高維複雜網絡時,拉普拉斯矩陣的維度會迅速膨脹到超出所有現有記憶體的儲存極限,更遑論進行對角化或奇異值分解(SVD)。
值得注意的是,即便是利用先進的古典演算法,或者試圖透過古典模擬量子電路的技術(例如利用穩定子形式 Stabilizer formalism 來處理部分問題),也無法有效破解這種純粹基於組合數爆炸的複雜度壁壘。這是一個本質上需要龐大記憶體空間與驚人算力的代數幾何難題。
四、 量子計算的破局之道:從指數複雜度到多項式時間
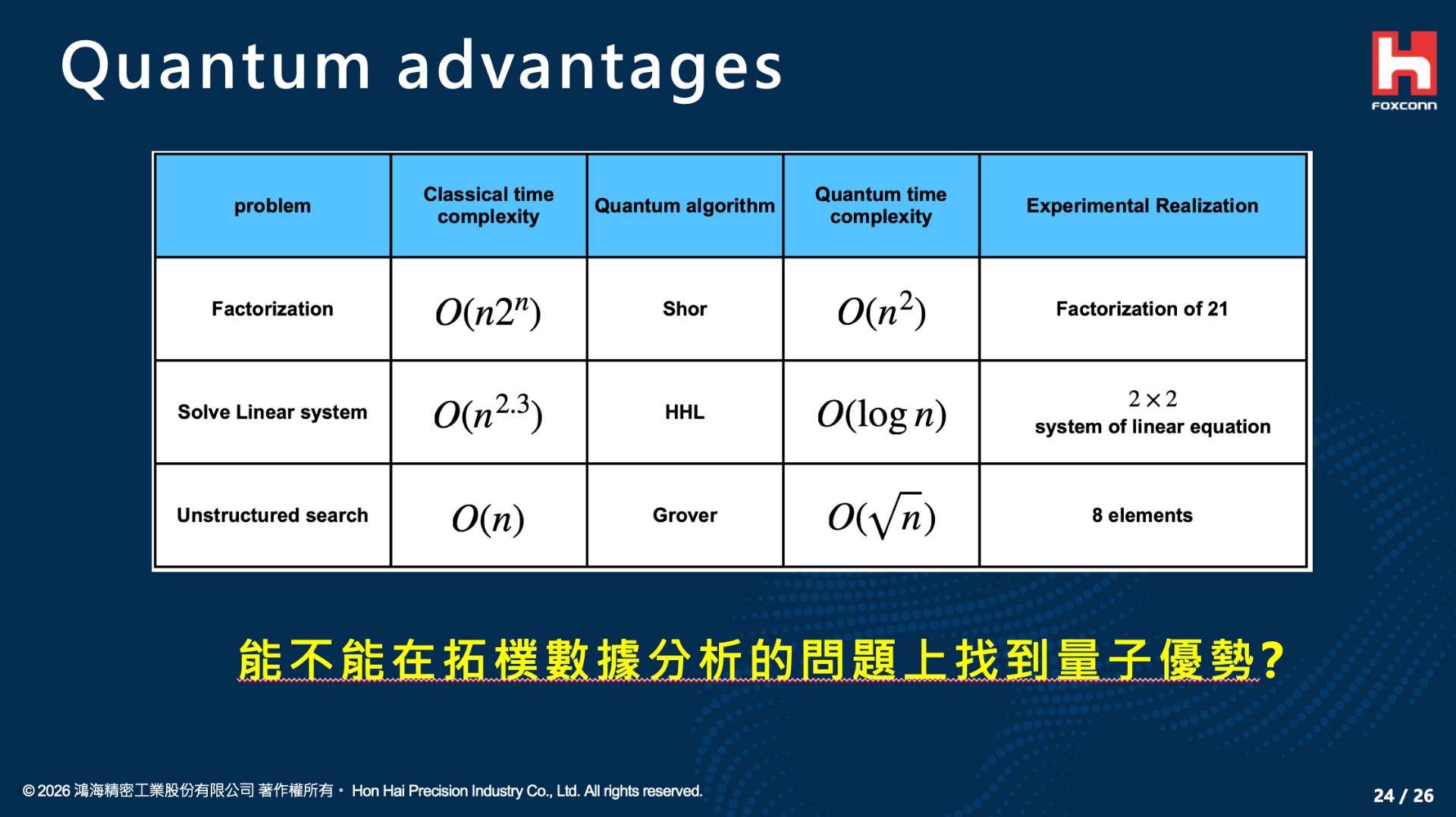
面對這項看似無解的古典難題,量子演算法展現出了絕對的計算優勢(Computational Advantage),這也是我們在量子計算領域投入研究的核心焦點。最著名的代表便是 Lloyd-Garnerone-Zanardi (LGZ) 演算法,它巧妙地將拓樸特徵的計算轉化為量子系統中的本徵值問題。
希爾伯特空間的高效映射(Qubit Mapping):
古典計算的瓶頸在於記憶體,而量子力學的疊加態為我們提供了解決方案。對於 $N$ 個資料點,我們只需要 $N$ 個量子位元(Qubits),就能構建出一個具有 $2^N$ 維度的希爾伯特空間 $\mathcal{H}$。系統中的每一個基底態(例如 $|1010...0\rangle$)都可以直接對應到一個特定的單純形($1$ 代表該頂點包含於單純形中,$0$ 代表不存在)。這項映射成功將古典電腦所需的「指數級記憶體」壓縮為量子電腦上的「線性數量量子位元」。
建構拉普拉斯哈密頓量(Hamiltonian Formulation):
根據霍奇理論(Hodge Theory),第 $k$ 維的貝蒂數 $\beta_k$ 正好等於組合拉普拉斯算子 $\Delta_k$ 的零特徵值數量。在設計量子演算法時,我們將邊界算子與其伴隨算子映射為量子系統上的生成與湮滅算符,從而建構出對應的哈密頓量:
$$\Delta_k = \partial_k^\dagger \partial_k + \partial_{k+1} \partial_{k+1}^\dagger$$
尋找貝蒂數的問題,就此轉變為測量這個哈密頓量處於基態(特徵值為零)的機率。
量子相位估計(Quantum Phase Estimation, QPE):
這是量子演算法加速的核心引擎。透過將上述哈密頓量進行么正演化 $e^{-i\Delta_k t}$,我們可以使用 QPE 演算法來高精度地讀出系統的相位(即特徵值)。藉由統計測量結果中特徵值為零的比例,我們便能估計出零空間的維度,進而求得貝蒂數 $\beta_k$。相較於古典演算法的 $O(2^N)$ 複雜度,量子 TDA 演算法能在多項式時間 $O(poly(N))$ 內完成貝蒂數的估計,達成了理論上的指數級加速(Exponential Speedup)。
五、 結語與未來實踐的挑戰
最後,我們必須務實地看待未來的挑戰。雖然量子 TDA 演算法在數學框架下展現了令人驚嘆的計算優勢,確認了量子電腦處理高維拓樸資料的巨大潛力,但我們距離將其應用於真實世界的大型數據集(如金融市場預測、複雜新藥分子設計、高維機器學習等)仍有一段路要走。
在目前的含雜訊中型量子(NISQ)時代,硬體的限制是最大的阻礙。量子 TDA 所依賴的量子相位估計(QPE)需要執行深度的量子線路,這在現有的量子硬體上極易受到退相干(Decoherence)與各種 Pauli 雜訊的破壞。因此,這項技術要達到真正的實用化,未來絕對必須仰賴容錯量子計算(Fault-Tolerant Quantum Computing, FTQC)的實現。這不僅需要硬體層面減少雜訊,更需要搭配具有高效編碼率與良好距離特性的量子錯誤更正代碼(例如量子低密度奇偶檢查碼 qLDPC)來保護深層線路的邏輯量子位元。
總結來說,這不僅是一場數學與物理的精彩交響,更清楚地指出了量子計算的未來藍圖。資料確實有形狀,而唯有具備容錯能力的量子演算法,才是我們看清這些高維輪廓、解鎖下一世代運算極限的最強大顯微鏡。


